
Hi all, Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective. Thanks, Anna
{kind=link}

Hi Anna, It’s a good question! I have used data from Discord to guide my research on organizing around technology design, culminating in my book Recoding Politics for MIT Press. From an ethical perspective, I consider Discord servers to be semi-private. That is, I don't consider the data these communities produce to be “public.” Therefore—and despite the frequently spicy and extremely quotable takes found on these servers—I didn’t quote or otherwise analyze data from Discord servers. However, I used insights gained from Discord-based discussions to guide my research. For example, I could use conversations to locate interview subjects with particular types of knowledge valuable for my research and obtain consent in a traditional fashion at the start of each interview. I haven’t had much experience collecting Discord data from a legal perspective, given that I’m now an independent researcher. However, if we understand “scraping” as an automated process, “scraping our services” is a strangely vague phrase. It seems to leave open the possibility for humans to retrieve data in ways that don’t “do harm to Discord” (whatever that means). If I were wording an IRB application, I would not define your data collection method as “scraping” but something else—perhaps "collecting posts from an online message board.” Personally, all of this together—the legal and ethical sides of the equation—seems to mean that you could collect data from a Discord server if 1) you did so in a semi-automated, humanistic way (perhaps a laborious cut & paste over time) and 2) obtained the consent of the Discord community you were doing research with, allowing them collectively to consent and each member to opt-out if they so choose. But I’m curious, too—how have researchers handled this challenge? best Aure — Dr. Aure Schrock (they/he) Academic Editor and Writing Coach at Indelible Voice <https://www.indeliblevoice.com/> Personal and Professional Links: bio.site/aure <http://bio.site/aure>
On Dec 18, 2024, at 8:42 AM, Anna Gjika via Air-L <air-l@listserv.aoir.org> wrote:
Hi all,
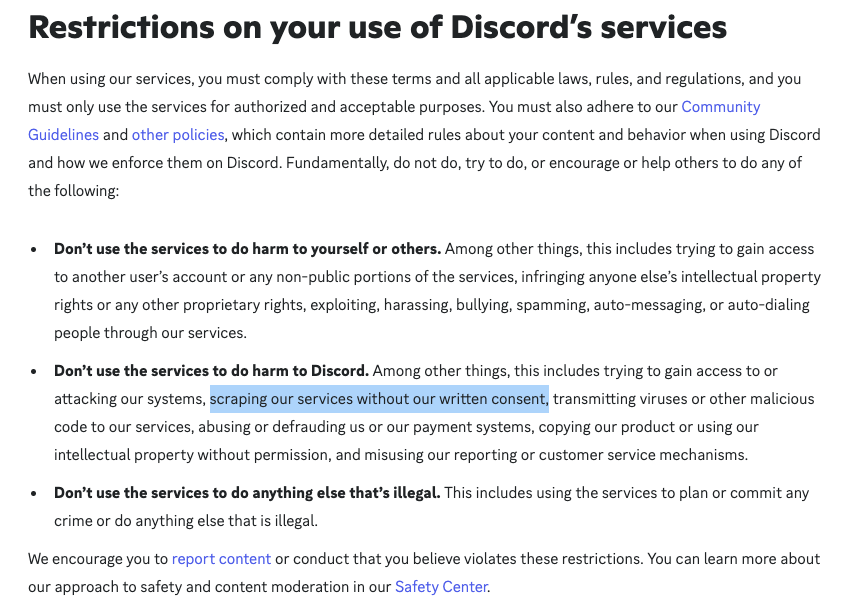
Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective.
Thanks, Anna <Screenshot 2024-12-18 at 7.56.18 AM.png>_______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/

Dear Anna and Aure, We have spent a considerable amount of time grappling with these questions in the context of a large-scale qualitative project on meme-based hate that I am currently running. First, I believe it is important to prioritize ethics as our primary concern, followed by GDPR, and then terms of service. Terms of service may be breached if the overarching (macro) ethical justification is compelling enough. Secondly, we have argued that platforms should not be viewed strictly as either public or private but should instead be evaluated based on the specific servers in question. We have written a paper that provides this assessment and outlines the circumstances under which we consider a server to be public. You can find the paper here (open access): Intrusiveness and the Public-Private Divide in Netnography. https://doi.org/10.1177/16094069241257937. Regarding GDPR and terms of service, if we were to engage in web scraping, we would likely collect a significant amount of personally identifiable information, as well as more data than necessary. For this reason, I completely agree with Aure's position that we should aim to collect only minimal and highly specific data. Additionally, it is crucial to ensure that any collected data is anonymized and non-personally identifiable in compliance with GDPR. For data collection, we have been using bespoke software (Manuscrape.org —open source) designed specifically for this purpose as it has an build in editor to remove (blank out) any data you now what to sit with if you make use of screenshots in your ethnography. Hope these reflections could be of help to move on in your project. Kind regards and happy holidays, Jakob Demant Professor PhD University of Copenhagen Department of Sociology Øster Farimagsgade 5, Postboks 2099 1014 København K DIR +45 35 32 15 84 MOB +45 81 74 20 74 jd@soc.ku.dk http://www.soc.ku.dk/ ManuScrape. Manage your digital ethnographic qualitative projects. ManuScrape.org Intrusiveness and the Public-private Divide in Netnography. https://doi.org/10.1177/16094069241257937 The Gut Feeling of Rational Acting https://doi.org/10.1177/10575677241241072 Drug dealing on Facebook, Snapchat, and Instagram: https://doi.org/10.1111/dar.12932 How we protect personal data -----Oprindelig meddelelse----- Fra: Air-L <air-l-bounces@listserv.aoir.org> På vegne af Aure Schrock via Air-L Sendt: 18. december 2024 19:12 Til: air-l@listserv.aoir.org Emne: Re: [Air-L] Discord data Hi Anna, It’s a good question! I have used data from Discord to guide my research on organizing around technology design, culminating in my book Recoding Politics for MIT Press. From an ethical perspective, I consider Discord servers to be semi-private. That is, I don't consider the data these communities produce to be “public.” Therefore—and despite the frequently spicy and extremely quotable takes found on these servers—I didn’t quote or otherwise analyze data from Discord servers. However, I used insights gained from Discord-based discussions to guide my research. For example, I could use conversations to locate interview subjects with particular types of knowledge valuable for my research and obtain consent in a traditional fashion at the start of each interview. I haven’t had much experience collecting Discord data from a legal perspective, given that I’m now an independent researcher. However, if we understand “scraping” as an automated process, “scraping our services” is a strangely vague phrase. It seems to leave open the possibility for humans to retrieve data in ways that don’t “do harm to Discord” (whatever that means). If I were wording an IRB application, I would not define your data collection method as “scraping” but something else—perhaps "collecting posts from an online message board.” Personally, all of this together—the legal and ethical sides of the equation—seems to mean that you could collect data from a Discord server if 1) you did so in a semi-automated, humanistic way (perhaps a laborious cut & paste over time) and 2) obtained the consent of the Discord community you were doing research with, allowing them collectively to consent and each member to opt-out if they so choose. But I’m curious, too—how have researchers handled this challenge? best Aure — Dr. Aure Schrock (they/he) Academic Editor and Writing Coach at Indelible Voice <https://www.indeliblevoice.com/> Personal and Professional Links: bio.site/aure <http://bio.site/aure>
On Dec 18, 2024, at 8:42 AM, Anna Gjika via Air-L <air-l@listserv.aoir.org> wrote:
Hi all,
Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective.
Thanks, Anna <Screenshot 2024-12-18 at 7.56.18 AM.png>_______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir/. org%2F&data=05%7C02%7Cjd%40soc.ku.dk%7C939b693f9d544b6acafb08dd1f91497 8%7Ca3927f91cda14696af898c9f1ceffa91%7C0%7C0%7C638701431050870335%7CUn known%7CTWFpbGZsb3d8eyJFbXB0eU1hcGkiOnRydWUsIlYiOiIwLjAuMDAwMCIsIlAiOi JXaW4zMiIsIkFOIjoiTWFpbCIsIldUIjoyfQ%3D%3D%7C0%7C%7C%7C&sdata=jo2EzD%2 FW3lNCI1vnB2hQdaD1E72GYvZeL%2FxB7l%2FFWO0%3D&reserved=0 Subscribe, change options or unsubscribe at: http://lists/ erv.aoir.org%2Flistinfo.cgi%2Fair-l-aoir.org&data=05%7C02%7Cjd%40soc.k u.dk%7C939b693f9d544b6acafb08dd1f914978%7Ca3927f91cda14696af898c9f1cef fa91%7C0%7C0%7C638701431050883649%7CUnknown%7CTWFpbGZsb3d8eyJFbXB0eU1h cGkiOnRydWUsIlYiOiIwLjAuMDAwMCIsIlAiOiJXaW4zMiIsIkFOIjoiTWFpbCIsIldUIj oyfQ%3D%3D%7C0%7C%7C%7C&sdata=NIQSXkCXeO8Ruf3mLXpGJDDlu%2BqSntYsMs9QNJ p05SQ%3D&reserved=0
Join the Association of Internet Researchers: http://www.a/ oir.org%2F&data=05%7C02%7Cjd%40soc.ku.dk%7C939b693f9d544b6acafb08dd1f9 14978%7Ca3927f91cda14696af898c9f1ceffa91%7C0%7C0%7C638701431050896811% 7CUnknown%7CTWFpbGZsb3d8eyJFbXB0eU1hcGkiOnRydWUsIlYiOiIwLjAuMDAwMCIsIl AiOiJXaW4zMiIsIkFOIjoiTWFpbCIsIldUIjoyfQ%3D%3D%7C0%7C%7C%7C&sdata=hPYb hm2Pb3A9TAyP%2Br9tJfLHpgfTCwGDbAUSKNCA9NM%3D&reserved=0
_______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org/ Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org Join the Association of Internet Researchers: http://www.aoir.org/

Hi Anna and AoIR friends! Glad to see this conversation happening--this is a subject that folks over in the Discord Academic Research Community (lovingly called the D/ARC; https://darcmode.org) have been discussing for a while! As you've pointed out, so much of the language that exists around ethics and social platforms assumes that "privacy" is obvious and paramount, when the question of "private data" is complicated and even unhelpful as a framework for approaching Discord. Quite fortuitously, the D/ARC leadership team just published a blog post on precisely this subject that might be of interest to folks here: https://darcmode.org/ethics-101/. How do we (succinctly and effectively) argue that a Discord server or channel is private or public? All Discord servers are fundamentally "invite only," but some are "Verified" or "Community-Enabled" or "Discoverable" in Discord's internal search. For this very reason, we've had members be told wildly different things by review committees, from "All data on Discord is protected, because all servers are invite only!" to "Well, it's kind of like a forum, so it's all public and you don't need an ethics review!" The use of scrapers, especially bots and third-party integrations, to collect data has also been met with varying confusion. I'm glad to say there's forthcoming research in this area from folks in our community, which hopefully will add some meaningful literature and methods. As we mention in the blog post above, we're actively looking for further resources/tools/literature scholars are using when it comes to conducting research on/about Discord. If you have others we don't have listed, please let us know and if you're doing Discord-related stuff and haven't joined our cheery corner of the internet, we'd be glad to hear about what you're working on! :) Best wishes, ✨ PB On Wed, Dec 18, 2024 at 9:59 AM Anna Gjika via Air-L < air-l@listserv.aoir.org> wrote:
Hi all,
Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective.
Thanks, Anna _______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/
-- Dr. PS Berge, PhD (they/her) *Assistant Professor of Experimental Game Design* Media & Technology Studies Program Department of Women's and Gender Studies University of Alberta Study Media & Make Games 🌐 psberge.com | 🦋 @iceberge <https://bsky.app/profile/iceberge.bsky.social>
Thank you all for your thoughtful responses. They seem to confirm what I suspected, which is that it's more about the data collection method, and that scraping wholesale could be the issue. In an ideal world consent would be great, but as Jakob notes, when conducting certain types of research - whether it's hate speech or online harassment, deepfakes etc. (my areas of research) this isn't always possible. I really appreciate the resources and language here around public/private and ethics. And how neat, there's a whole Discord research community, with some excellent walk through questions - thanks PS! Wishing you all a happy and restorative holiday season! Anna On Wed, Dec 18, 2024 at 6:13 PM PS Berge via Air-L <air-l@listserv.aoir.org> wrote:
Hi Anna and AoIR friends!
Glad to see this conversation happening--this is a subject that folks over in the Discord Academic Research Community (lovingly called the D/ARC; https://darcmode.org) have been discussing for a while! As you've pointed out, so much of the language that exists around ethics and social platforms assumes that "privacy" is obvious and paramount, when the question of "private data" is complicated and even unhelpful as a framework for approaching Discord. Quite fortuitously, the D/ARC leadership team just published a blog post on precisely this subject that might be of interest to folks here: https://darcmode.org/ethics-101/.
How do we (succinctly and effectively) argue that a Discord server or channel is private or public? All Discord servers are fundamentally "invite only," but some are "Verified" or "Community-Enabled" or "Discoverable" in Discord's internal search. For this very reason, we've had members be told wildly different things by review committees, from "All data on Discord is protected, because all servers are invite only!" to "Well, it's kind of like a forum, so it's all public and you don't need an ethics review!" The use of scrapers, especially bots and third-party integrations, to collect data has also been met with varying confusion. I'm glad to say there's forthcoming research in this area from folks in our community, which hopefully will add some meaningful literature and methods.
As we mention in the blog post above, we're actively looking for further resources/tools/literature scholars are using when it comes to conducting research on/about Discord. If you have others we don't have listed, please let us know and if you're doing Discord-related stuff and haven't joined our cheery corner of the internet, we'd be glad to hear about what you're working on! :)
Best wishes, ✨ PB
On Wed, Dec 18, 2024 at 9:59 AM Anna Gjika via Air-L < air-l@listserv.aoir.org> wrote:
Hi all,
Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective.
Thanks, Anna _______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/
--
Dr. PS Berge, PhD (they/her)
*Assistant Professor of Experimental Game Design*
Media & Technology Studies Program
Department of Women's and Gender Studies
University of Alberta
Study Media & Make Games
🌐 psberge.com | 🦋 @iceberge <https://bsky.app/profile/iceberge.bsky.social> _______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/

Dear Anna and everyone! Happy new year first of all. I hope you all had a restful break. The conversation here is fascinating concerning data scraping/collection from DISCORD. I was wondering if the community here could also help me with a similar query regarding suitable data collection methods for social media platforms. Can colleagues here share any relevant methods of data collection they may have used or know of for X (former Twitter), Instagram and Facebook? This is in regard to research to understand political content online. Any suggestions/leads would be greatly appreciated. Warm regards Preeksha On Fri, Dec 20, 2024 at 12:59 AM Anna Gjika via Air-L < air-l@listserv.aoir.org> wrote:
Thank you all for your thoughtful responses. They seem to confirm what I suspected, which is that it's more about the data collection method, and that scraping wholesale could be the issue. In an ideal world consent would be great, but as Jakob notes, when conducting certain types of research - whether it's hate speech or online harassment, deepfakes etc. (my areas of research) this isn't always possible. I really appreciate the resources and language here around public/private and ethics.
And how neat, there's a whole Discord research community, with some excellent walk through questions - thanks PS!
Wishing you all a happy and restorative holiday season!
Anna
On Wed, Dec 18, 2024 at 6:13 PM PS Berge via Air-L < air-l@listserv.aoir.org> wrote:
Hi Anna and AoIR friends!
Glad to see this conversation happening--this is a subject that folks over in the Discord Academic Research Community (lovingly called the D/ARC; https://darcmode.org) have been discussing for a while! As you've pointed out, so much of the language that exists around ethics and social platforms assumes that "privacy" is obvious and paramount, when the question of "private data" is complicated and even unhelpful as a framework for approaching Discord. Quite fortuitously, the D/ARC leadership team just published a blog post on precisely this subject that might be of interest to folks here: https://darcmode.org/ethics-101/.
How do we (succinctly and effectively) argue that a Discord server or channel is private or public? All Discord servers are fundamentally "invite only," but some are "Verified" or "Community-Enabled" or "Discoverable" in Discord's internal search. For this very reason, we've had members be told wildly different things by review committees, from "All data on Discord is protected, because all servers are invite only!" to "Well, it's kind of like a forum, so it's all public and you don't need an ethics review!" The use of scrapers, especially bots and third-party integrations, to collect data has also been met with varying confusion. I'm glad to say there's forthcoming research in this area from folks in our community, which hopefully will add some meaningful literature and methods.
As we mention in the blog post above, we're actively looking for further resources/tools/literature scholars are using when it comes to conducting research on/about Discord. If you have others we don't have listed, please let us know and if you're doing Discord-related stuff and haven't joined our cheery corner of the internet, we'd be glad to hear about what you're working on! :)
Best wishes, ✨ PB
On Wed, Dec 18, 2024 at 9:59 AM Anna Gjika via Air-L < air-l@listserv.aoir.org> wrote:
Hi all,
Has anyone worked with data from Discord? They have the following in their ToS, and I'm curious how folks have dealt with this from a methodological/ ethics review board perspective.
Thanks, Anna _______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/
--
Dr. PS Berge, PhD (they/her)
*Assistant Professor of Experimental Game Design*
Media & Technology Studies Program
Department of Women's and Gender Studies
University of Alberta
Study Media & Make Games
🌐 psberge.com | 🦋 @iceberge <https://bsky.app/profile/iceberge.bsky.social> _______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/
_______________________________________________ The Air-L@listserv.aoir.org mailing list is provided by the Association of Internet Researchers http://aoir.org Subscribe, change options or unsubscribe at: http://listserv.aoir.org/listinfo.cgi/air-l-aoir.org
Join the Association of Internet Researchers: http://www.aoir.org/
-- Warm Regards Preeksha
participants (5)
-
 Anna Gjika
Anna Gjika -
 Aure Schrock
Aure Schrock -
 Jakob Johan Demant
Jakob Johan Demant -
 Preeksha Malhotra
Preeksha Malhotra -
 PS Berge
PS Berge